完成了计算机应用编程的第一个实验,有必要进行一些总结。一直没抽空出来把第一个实验的报告进行总结,今天假期,正好把这个问题进行一下总结。 大规模字符串的查找问题定义的是在一个有千万级别的字符串中查找相应的字符串存在不存在,若存在输出yes,否则输出no。这项技术被广泛用在一些场合,如进行EMail地址过滤,要求在ms级别的时间内进行查找,但是相反对于程序启动的时间却没有要求,只要求查找速度尽量快。所以提出了进行建树。本文主要整理了Trie树、Trie树的压缩的相关算法,作为参考。 本次作业以查找Email为例,代码详见:EmailSearch。
1. Trie树
Trie树是一颗多叉树,实际上是一个DFA,每一个节点的孩子表示这个字符是否存在,若存在指向下一个节点,若不存在,则指向NULL。所以在搜索时,只用从头节点开始,顺序搜索即可。具体详见wiki 为了实现这样一个Trie树,我们采用的数据结构是这样的:
struct trieTree{
int isEmail;
struct trieTree *next[63];
};//saved in trie.h
使用这个作为树的节点,Email中含有字符串0-9,A-Z,a-z,’@’,’.’,还有一些非标准字符串,总共63个字符。显而易见,这样的Trie树节点存储效率很低。我们的输入数据有1kW行Email地址。实际测试中,64bit的操作系统中,我们使用了60G的内存,再加上一些Swap,也只建树了640W左右个Email地址,真是浪费内存。最主要的是在叶子节点上,只用了一个isEmail字段,但是仍然要分配63个指针。在64bit的系统下,每个指针占用内存为8字节,在加上一个整型数,光存储叶子节点就需要1kw648B=5G。 所以,我们就把Trie树后面的静态数组,变为链表。虽然增加了查找的时间,但是减少了内存的消耗,尤其是叶子节点的内存占用。其数据结构如下:
typedef struct sNodeList NODELIST;
typedef struct trieTree TRIE;
struct sNodeList {
char c; //存储字符
TRIE *tnext; //下一个子节点位置
struct sNodeList *next; //下一个字符的位置
};
struct trieTree{
int isEmail; //是否为字符串
struct sNodeList *list; //标记节点
};//saved in listtrie.h
采用链表的方式来保存后续的节点,这样就能够很好的节省内存。其插入过程如下图:
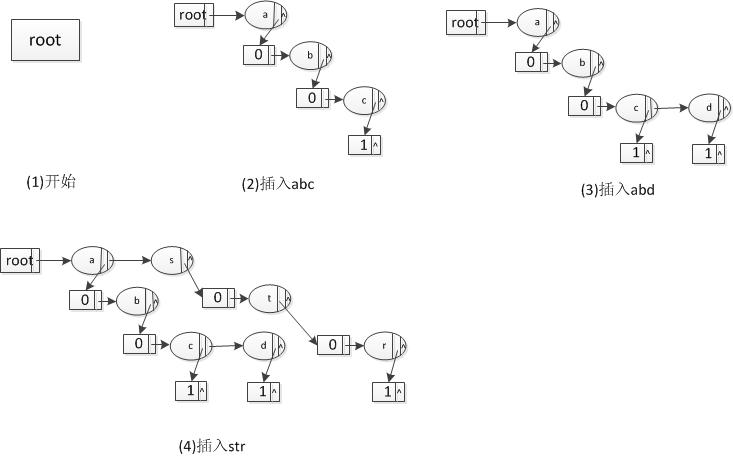 使用这样的一个数据结构,能够比较好的减少内存开支,大概使用了15G左右的内存,就能完成整个查询。其中,主要是叶子节点占用的内存较多
使用这样的一个数据结构,能够比较好的减少内存开支,大概使用了15G左右的内存,就能完成整个查询。其中,主要是叶子节点占用的内存较多
2.压缩Trie树
在Trie树中,我们存储的是字符,很多情况下,我们会有如下图的情况。
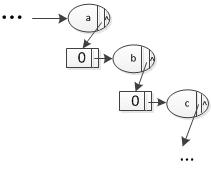
为了解决Trie树中有这样孤立的一串字符节点,我们采用了压缩trie树的方法。这是一个典型的压缩trie树的插入过程:
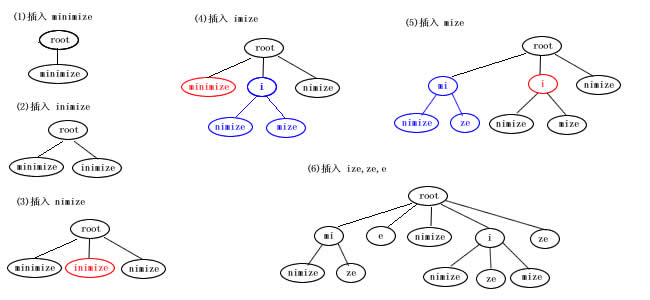 采用上面的数据结构,我们只需要将上面的
采用上面的数据结构,我们只需要将上面的char c换为char *str。这种方法的关键是比较两个字符串有多少个字母相同,具体的数据结构,详见clisttrie.h
在使用这样的压缩trie之后,我们的程序只需3.31G就能够完成了整个程序,而且时间比之前的程序还少了。
虽然这已经减少了内存的占用,但是我们还是浪费了一些内存。所以我们将这棵树转变为二叉树,用二叉树的方式来处理这个节点,问题就回到了二叉树上来。
定义的代码如下:
typedef struct trieTree TRIE;
struct trieTree{
short int isEmail;
char *str;
TRIE *bro;
TRIE *son;
};//in clisttrie2.h
其二叉树的插入过程如下:
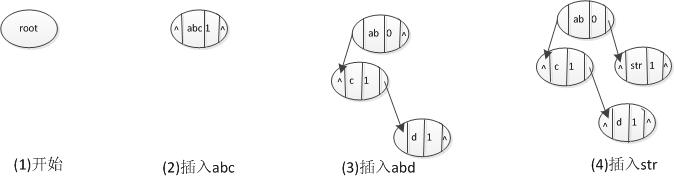
非常简洁的一个表达,左孩子右兄弟,通过这样的简化,可以减少内存占用。我们实际运行的时候,只用了1G就把这个程序运行完毕。也是一个不错的简化。
3. 其他
在github中,testfile中放着的是其他组的trie树的实现代码。data.ods是每组花费的时间。也可以看看其他组如何实现。还想顺便把Bloom过滤器给补上了。等后面吧。初次使用Markdown语言,还请见谅。 花了一晚上时间,用来总结。还是值得的。