SimpleSpider
一、功能分析
这个使用C语言实现了一个基本的网络爬虫,目前(2015年1月24日)为止,主要设计的内容有链接分析、网页抓取。程序使用libevent(2.0.21-stable)来进行socket连接处理,使用自动机进行链接分析(详情见下文)。 本程序要求:
- 从给定网址作为入口,爬取对应入口网页并分析其中的URL并爬取对应的网页,直到没有更多页面爬取时完成
- 爬取时只爬取本地服务器的网页,不怕取外站资源
- 采用多线程结构设计,输出每一个文件的文件大小
使用方法:
make./crawler entrance_url out_put_file
二、架构设计
本系统整体架构如下所示,由主线程、抓取线程、分析分配线程和分析线程五类线程组成。线程间的通信主要使用一个轻量级消息队列Nanomsg来进行。主线程主要负责抓取线程和分析分配线程的创建。抓取线程主要负责网页的Socket的抓取,并将得到的网页内容放到队列中。分析分配线>程主要负责从消息队列中提取得到的网页内容,并将其分配到分析进程的进程池中对应的线程进行计算。分析线程主要负责从得到网页内容中解>析出地址并放到消息队列中。
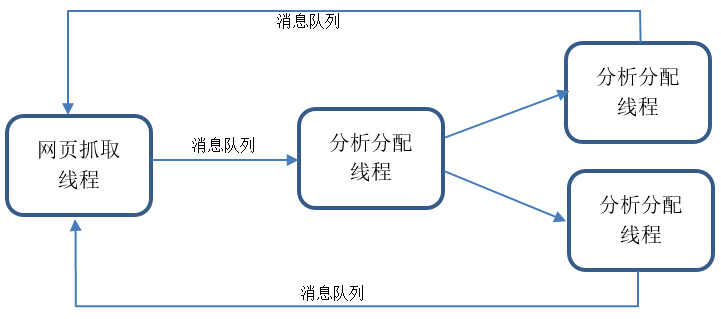
三、核心线程的设计
1、网页抓取线程
网页抓取线程主要是负责的是网页的socket抓取,并且将抓取的内容放到nanomsg中。网页抓取线程采用的是Libevent库来进行网络的连接和抓取,Libevent库是一个基于Reactor模型的一个网络库,支持异步的调用函数。只需在初始化的时候在相应时间上一个函数,程序就会在该事件发生时调用对应的函数库。
1.Bufferevents和Evbuffer
Libevent在event事件调用的基础上,又在之上封装了一个Bufferevents,主要用于面向流的通讯,其类似Java的输入输出流,通过指定IP地址和端口,就能直接进行读写。在Bufferevents中封装了两个Evbuffer类型的指针,一个是input,另外一个是output。Evbuffer类型主要用于存储字符串内容,是一个能够用在网络编程的缓冲区,类似C++中的String类型。只要一次定义,可以无限的进行读取和写入而不用担心缓冲区溢出的问题。但是在bufferevent中,每次读取的字节数只能是4096个字节。对于大量的数据,这个缓冲区大小是比较小的,这个可以通过调整源码进行修改。
2.HTTP的keep-alive
HTTP包头的keep-alive能够保证在每一次传输完成后保持连接可以继续下一次的数据传递,这样可以大大节省每次打开和关闭TCP连接的时间开销。但是keep-alive并不是无限次的,不同的HTTP服务器默认对keep-alive的请求次数和超时时间的设置是不一样的。Apache默认的keep-alive请>求次数是100次,超时时间是5s。Nginx默认的请求次数也是100次,但是超时时间是75s。 在请求HTTP包的时候,其请求顺序是发送一个HTTP请求包,HTTP服务器就会返回相应的请求页面,待当前页面发送完成后,再接收下一个HTTP请>求包。而不是能够一直接受HTTP请求包。
3.HTTP包头分析
在处理HTTP连接时,需要进行HTTP包头的分析。HTTP包头的处理也是一个状态机,其状态机的转换如下所示。在分析HTTP包头时,对于目前的爬>虫,仅仅需要得到HTTP状态和content-length的值。所以目前的HTTP包头分析比较简单。
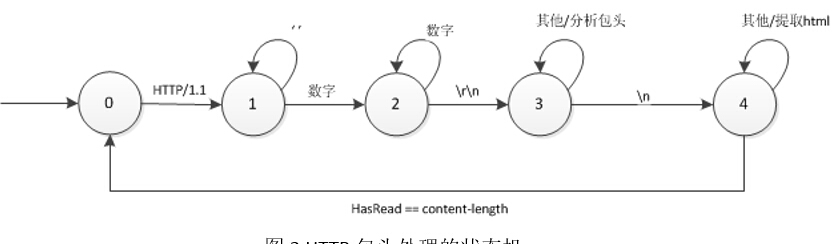
2、分析线程 分析线程将接收到的HTML语言,使用状态机的方法分析HTML中出现的链接,将外站的连接去除,只留下本地链接,并将本地链接中含有相对路径>的部分转换成为绝对地址链接。
####1、HTML链接提取
HTML链接中的URL主要放在 <a> 标签中的href属性中,我们采用的状态机的方式提取出标签中的URL。分析时也需要去除href=”#”、href=”javascript::void(0)”等这样的无效链接,对于href=”a.html#a1”这样的锚点链接,我们要将后面的锚点去掉,只留下a.html。这样在去重的时候,能够保证不将a.html#a1和a.html#a2视为两个链接。本程序使用的状态机如下所示。
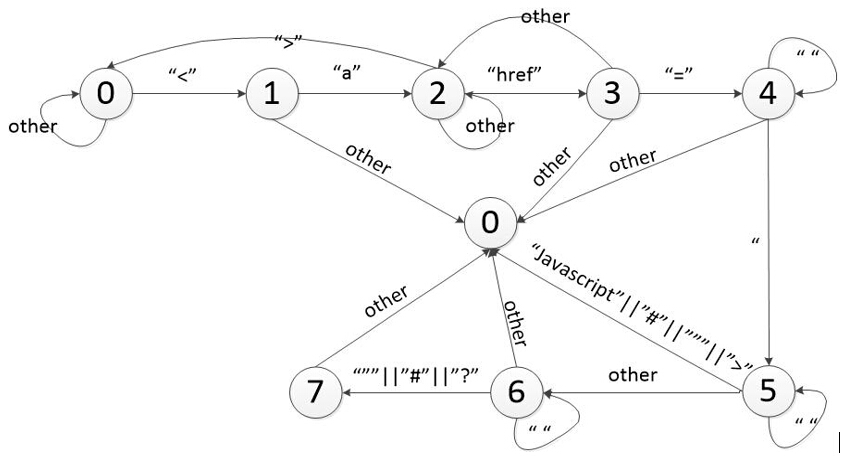
使用状态机的好处是简单易行,相比起解析HTML DOM模型能够更加高效的解析出URL地址,但是由于这个解析器不够完备,只能解析出<a>标签>中href属性的地址。还有一些包含在<iframe>、<table> 标签backgroud属性等的网页链接地址、还有Ajax中的页面,是不能够被这个状态机分析到的。这里需要引入一个模拟浏览器来进行分析。
2、URL转换
HTTP包的请求地址中是不能含有相对链接的,而且使用相对链接对于去重也是比较复杂的,所以我们需要将我们抓到的URL链接转换成为绝对链接,同时也要去除外站地址,避免我们的程序爬取到外站的链接导致程序无法收敛。
在转换相对链接是,需要转换诸如 ../../a.html、a.html、/a.html这样的链接,转换成为对应的相对地址。
3、URL地址的去重
为了避免重复的抓取相同的URL地址,在本程序中URL去重。在本次实验中,使用的是实验一大规模字符串查找中的TRIE树来进行查重。在使用TRIE树的时候,需要注意进行线程的同步。由于上一个实验的代码是单线程的程序,所以TRIE树的插入、查找的操作也是单线程的。所以在使用时需要用pthread_mutex_t来进行线程间的同步与互斥操作。
3、消息队列
消息队列采用的是Nanomsg库,这是一个使用C语言编写的一个消息队列,可以轻松完成跨线程、跨进程、跨机器的通讯。Nanomsg的通讯模式有NN_PAIR、NN_REPREQ、NN_PIPELINE等通讯模型。本程序采用的通讯模型主要是NN_PAIR的通讯模型,进行一对一的通讯。考虑到程序是在同一个进>程内运行,所以我们主要以传递指针为主。下图所示的就是两个进程通讯之间传递的数据类型:
Nanomsg中可以实现“零拷贝”,Send端采用:
void *msg = nn_allocmsg(3, 0);
strncpy(msg, "ABC", 3);
nbytes = nn_send (s, &msg, NN_MSG, 0);
assert (nbytes == 3);
发送端采用
void *buf = NULL;
nbytes = nn_recv (s, &buf, NN_MSG, 0);
if (nbytes < 0) {
/* handle error */
...
}
else {
/* process message */
...
nn_freemsg (buf);
}
这样的代码就能实现“零拷贝”。详见http://nanomsg.org/v0.4/nn_recv.3.html http://nanomsg.org/v0.4/nn_send.3.html
4、线程池
进程池线程主要采用的是threadpool.c和threadpool.h这两个文件。其中,create_threadpool函数新建了一个线程池,并将线程池进行初始化操作。在实际需要调用线程的时候,只需要使用dispatch函数,将要调用的函数指针、参数传递进去。线程池会自动给你调用执行并回收资源。通>过线程池可以很好的控制分析线程运行的个数,做到按需来分配线程,避免了因频繁生成和销毁线程造成的线程开销。
四、结果
经过多次运行,该程序总共分析出了363651个链接地址,有效链接地址为157396个网页。
五、TODOLIST
- 实现了简单的爬虫能够爬去
- 传输时加入zlib压缩
- 更好的http页面分析
- 加入IPv6支持,兼容IPv4和IPv6
- 修改Http包头分析,使用一些Bufferevents的新函数
- 考虑加入一个管理线程,进行
- 引入正文提取
- 使用Nanomsg,引入分布式,将线程分开